
2.1 Boltz-2 主干网络 (Trunk): Pairformer 架构
Boltz-2的主干网络(Trunk)是其结构预测能力的核心,其设计在很大程度上借鉴并扩展了前代模型的思想,其核心是Pairformer模块。与早期架构相比,Pairformer的一个关键演进是显著降低了对多序列比对(MSA)信息的直接和持续依赖,转而将计算重心完全放在对成对表示(pair representation)和单一表示(single representation)的深度迭代精炼上。这种设计使其能更高效地处理包含多种分子类型(蛋白质、核酸、小分子等)的复杂生物系统。
Pairformer 整体架构与数据流
Pairformer是Boltz-2主干网络中进行迭代优化的核心引擎。它接收初始的单一表示(描述每个残基/原子的特征)和成对表示(描述每对残基/原子间的关系),并通过一系列结构相同但参数独立的处理块(Blocks)进行循环精炼。
- 输入:
- 单一表示 (Single Representation) $s$:一个二维张量,尺寸为 $(n \times c_s)$,其中 $n$ 是系统中所有残基和原子(tokens)的总数,$c_s$ 是编码每个token自身属性的特征通道数。
- 成对表示 (Pair Representation) $z$:一个三维张量,尺寸为 $(n \times n \times c_z)$,其中 $c_z$ 是特征通道数。它编码了系统中每对token $(i, j)$ 之间的空间和化学关系。
-
处理流程:
- 初始的 $s$ 和 $z$ 矩阵,连同模板信息,被送入一个包含多个独立参数的Pairformer块的堆栈中进行处理。
- Boltz-2将此核心堆栈扩展到了64层,以增强模型的表达能力和性能。
- 在主循环中,信息主要在成对表示 $z$ 中通过三角更新(Triangle Updates)和三角自注意力(Triangle Self-Attention)进行横向传递和整合,以捕捉复杂的几何约束。
- 单一表示 $s$ 的信息通过一个带有成对偏置的注意力机制(
Single attention with pair bias)被更新,并反过来影响成对表示的计算。 - 整个主干网络的结果会通过“循环”(Recycling)机制多次反馈,将上一轮的输出作为下一轮的输入,进一步精炼表示。
-
输出:
- 经过64次迭代精炼后,主干网络输出最终的单一表示和成对表示。这些高度精炼的表示随后被送入扩散模块(Diffusion Module),用于直接生成最终的三维原子坐标。
以下是Pairformer整体架构的示意图:
graph TD
subgraph Boltz-2 Trunk
A_IN[初始单一表示 s] --> B_MSA[轻量化MSA模块];
TEMPLATE[模板信息] --> C_TEMPLATE[模板模块];
C_IN[初始成对表示 z] --> D_PAIR[Pairformer 核心循环];
B_MSA --> D_PAIR;
C_TEMPLATE --> D_PAIR;
subgraph D_PAIR [Pairformer 核心循环 「64个独立块」]
direction LR
INPUT_S["s_in"] --> BLOCK;
INPUT_Z["z_in"] --> BLOCK[Pairformer 块];
BLOCK --> OUTPUT_S["s_out"];
BLOCK --> OUTPUT_Z["z_out"];
end
D_PAIR -- "循环多次 「Recycling」" --> D_PAIR;
D_PAIR --> E_OUT[最终单一表示 s'];
D_PAIR --> F_OUT[最终成对表示 z'];
end
E_OUT --> G[扩散模块];
F_OUT --> G[扩散模块];
G --> H[原子坐标];
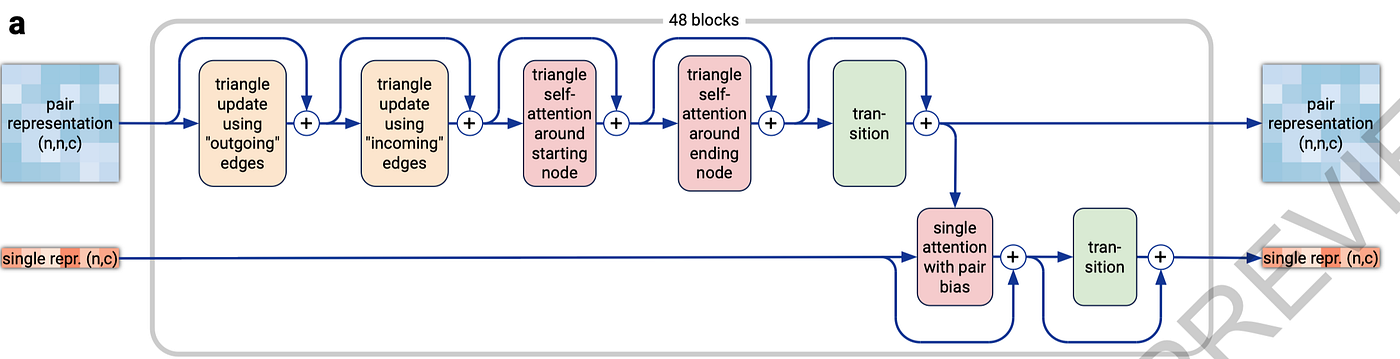
Pairformer 模块核心组件解析
每个Pairformer块内部由一系列精心设计的子模块构成,旨在高效地在成对表示中传播和整合信息。
graph LR
subgraph "单个Pairformer块内部流程"
Z_IN[输入 z_ij] --> TU_OUT[三角更新 「出边」];
TU_OUT --> TU_IN[三角更新 「入边」];
TU_IN --> TSA_START[三角自注意力 「起始节点」];
TSA_START --> TSA_END[三角自注意力 「结束节点」];
TSA_END --> TRANS_Z[过渡层 「z」];
S_IN[输入 s_i] --> S_ATT[单序列自注意力];
TRANS_Z -- "提供偏置" --> S_ATT;
S_ATT --> TRANS_S[过渡层 「s」];
TRANS_Z --> Z_OUT[输出 z_ij'];
TRANS_S --> S_OUT[输出 s_i'];
end
三角更新 (Triangle Update)
三角更新是Pairformer中一种不基于注意力的信息传播机制,其核心思想是利用几何上的三角关系来更新两个节点(i,j)之间的关系表示。它通过一个中间节点 $k$ 来传递信息:如果节点 $i$ 和 $k$ 之间的关系已知,并且节点 $k$ 和 $j$ 之间的关系也已知,那么这些信息就可以被整合用来推断和更新节点 $i$ 和 $j$ 之间的关系。这种机制在直觉上与三角不等式的几何约束思想相通,但在实现上是特征层面的信息整合。
该过程分为两个步骤:
- 基于出边的三角更新 (
Triangle update using outgoing edges): 对于每一对 $(i, j)$,它会遍历所有第三个节点 $k$,并整合从 $i$ 出发到 $k$ 的边 $(i, k)$ 和从 $j$ 出发到 $k$ 的边 $(j, k)$ 的信息。 - 基于入边的三角更新 (
Triangle update using incoming edges): 类似地,它会整合从 $k$ 进入到 $i$ 的边 $(k, i)$ 和从 $k$ 进入到 $j$ 的边 $(k, j)$ 的信息。
这些更新通常通过门控的乘法(multiplicative updates)实现,能够高效地在成对表示矩阵中传播结构信息。
三角自注意力 (Triangle Self-Attention)
三角自注意力的核心原理是,为了更新节点对 $(i, j)$ 的表示 $z_{ij}$,模型应该“关注”所有能与 $(i, j)$ 形成三角形的中间节点 $k$。这意味着 $z_{ij}$ 的更新会聚合来自所有边对 ${(i, k), (j, k)}$ 的信息。这使得模型能够学习到复杂的、高阶的残基间相互作用和空间约束。
该机制同样分为两个独立的模块:
- 起始节点为中心的三角自注意力 (
Triangle self-attention around starting node): 对于边 $(i, j)$,此模块的注意力计算主要关注从共享的起始节点 $i$ 出发到所有其他节点 $k$ 的边 $(i, k)$。 - 结束节点为中心的三角自注意力 (
Triangle self-attention around ending node): 对于边 $(i, j)$,此模块的注意力计算则关注汇聚到共享的结束节点 $j$ 的、来自所有其他节点 $k$ 的边 $(k, j)$。
数学表述 (以起始节点为例):
该过程遵循标准的多头自注意力(Multi-Head Self-Attention, MHSA)范式,但其Query, Key, Value的定义和组合方式体现了“三角”思想。对于需要更新的成对表示 $z_{ij}$,我们首先通过线性变换生成Query (q)、Key (k)和Value (v)向量。这里的关键在于,q 来自于目标边 $(i, j)$ 本身,而 k 和 v 来自于形成三角形的另一条边 $(i, k)$。
-
Query, Key, Value 的生成:
\[q_{ij} = W_q z_{ij} / k_{ik} = W_k z_{ik} / v_{ik} = W_v z_{ik}\]其中 $W_q, W_k, W_v$ 是可学习的权重矩阵。
-
注意力分数计算:
\[\alpha_{ijk} = \text{softmax}_k \left( \frac{q_{ij}^T k_{ik}}{\sqrt{d_k}} + b_{ik} \right)\]这里,注意力分数基于边 $(i, j)$ 和所有以 $i$ 为起点的边
补充流程图
AI生成,请自行甄别
总览
mindmap
root(Boltz-2<br/>核心特点总览)
::icon(fa fa-bolt)
**革命性的亲和力预测**<br/>「千倍加速,精度媲美FEP」
统一的通用框架<br/>「蛋白、核酸、配体」
**动态与系综建模**<br/>「学习MD/NMR数据<br/>预测B-factor」
**高度用户可控性**
方法条件化「X-ray, NMR, MD」
模板引导「支持多聚体,可软可硬」
口袋与接触约束「用户指定相互作用」
降低对MSA的依赖<br/>「提升单序列性能」
物理真实性校正<br/>「通过Boltz-steering<br/>减少碰撞、修正手性」
完全开源<br/>「模型、代码、数据<br/>均在MIT许可下发布」
当前局限<br/>「难捕捉大的构象变化<br/>未明确支持辅因子/离子」
结构预测流程
graph TB
subgraph " "
direction LR
subgraph "输入层 提供所有原始信息"
A["序列「蛋白、核酸」<br/>SMILES「小分子」"]
B["生物学上下文<br/>「MSA & 模板」"]
C["用户控制信息<br/>「口袋、约束、实验方法」"]
end
end
subgraph " "
TRUNK("<b>主干网络 「Trunk」</b><br/>大脑:提取深层特征<br/>核心技术: Pairformer 堆栈<br/>输出: <b>单一表示 & 成对表示</b>")
end
A --> TRUNK
B --> TRUNK
C --> TRUNK
subgraph "三大并行的预测模块"
direction LR
STRUCT("<b>1. 结构预测模块</b><br/>「生成器:雕刻3D结构」<br/>技术: 扩散模型<br/>可选: Boltz-steering 物理校正")
CONF("<b>2. 置信度预测模块</b><br/>「质检员:评估结构质量」<br/>输入: 主干网络表示 + 预测的3D结构<br/>输出: 置信度分数「pLDDT、ipTM等」")
AFF("<b>3. 亲和力预测模块</b><br/>「审判官:判定结合强度」<br/>输入: 主干网络表示 + 预测的3D结构<br/>输出: 结合可能性 & 亲和力值")
end
TRUNK -- "内部表示" --> STRUCT
TRUNK -- "内部表示" --> CONF
TRUNK -- "内部表示" --> AFF
STRUCT -- "预测的3D原子结构" --> CONF
STRUCT -- "预测的3D原子结构" --> AFF
style TRUNK fill:#fff3e0,stroke:#fb8c00,stroke-width:2px
style STRUCT fill:#e3f2fd,stroke:#1e88e5,stroke-width:2px
style CONF fill:#e8f5e9,stroke:#4caf50,stroke-width:2px
style AFF fill:#fce4ec,stroke:#d81b60,stroke-width:2px
MD数据整合
| 数据集名称 | 主要内容 | 模拟细节 | 数据采样/筛选策略 | 最终规模 | 来源文献 |
|---|---|---|---|---|---|
| MISATO | 蛋白质-小分子配体复合物 | NVT系综,300K,8 ns | 移除配体漂移(>12Å)或含聚糖/修饰肽的轨迹使用全部100帧 | 11,235个系统 | Siebenmorgen et al. (2024) |
| ATLAS | 蛋白质 | NPT系综,300K,100 ns | 从轨迹最后10ns中随机均匀采样100帧 | 1,284个蛋白质 | Vander Meersche et al. (2024) |
| mdCATH | 蛋白质 | NVT系综,320K,时长可变(最长500ns) | 仅使用轨迹最后10%进行训练 | 5,270个系统 | Mirarchi et al. (2024) |
graph TD
subgraph "Boltz-2的MD数据整合评估"
direction LR
subgraph "性能评估「如何衡量动态预测能力」"
direction TB
C["<b>基于RMSF的指标</b>"]
C --> C1["计算方法: Boltz-2生成预测系综<br/>计算其RMSF并与真实MD轨迹的RMSF比较"]
C --> C2["具体指标: Pearson R, Spearman ρ, RMSE"]
D["<b>基于lDDT的系综指标</b>"]
D --> D1["<b>Precision lDDT</b><br/>「预测构象的合理性」"]
D --> D2["<b>Recall lDDT</b><br/>「对真实构象多样性的覆盖度」"]
D --> D3["<b>Diversity lDDT</b><br/>「预测系综自身的多样性」"]
end
subgraph "训练方法「AI如何学习动态过程」"
direction TB
A["<b>系综监督 (Ensemble Supervision)</b>"]
A --> A1["聚合距离图监督<br/>「学习系综的平均空间特征」"]
A --> A2["随机坐标监督<br/>「从系综中随机采样单帧<br/>用于坐标去噪训练」"]
B["<b>B-factor 监督</b>"]
B --> B1["学习原子级的局部柔性<br/>「通过RMSF计算B-factor作为监督信号」"]
end
end
style A fill:#e3f2fd,stroke:#1e88e5,stroke-width:2px
style B fill:#e3f2fd,stroke:#1e88e5,stroke-width:2px
style C fill:#e8f5e9,stroke:#4caf50,stroke-width:2px
style D fill:#e8f5e9,stroke:#4caf50,stroke-width:2px
亲和力训练
图一:数据采样与批次组装流程
这张图的核心是展示Boltz-2如何智能地从庞大的数据源中,为每一个训练批次(batch)精心挑选出信息量最大的样本。
graph TD
subgraph "图一:数据采样与批次组装流程"
F["开始一个训练批次"] --> G{"选择数据源<br/>「连续值 vs. 二元标签」"};
G -- "连续值亲和力" --> H("<b>活性悬崖采样器</b><br/>根据IQR分数优先选择信息量大的实验");
G -- "二元标签" --> I("<b>结合物-诱饵采样器</b><br/>确保1个结合物配对4个同实验的诱饵");
H --> J["采样一批「5个」<br/>来自同一实验的分子"];
I --> J;
J --> K{"组装批次数据"};
subgraph "输入自阶段一的预处理数据"
C_IN["已缓存的共识口袋"];
E_IN["预计算的Trunk特征"];
end
C_IN -- "用于裁剪" --> K;
E_IN -- "提供特征" --> K;
K --> K_OUT(["产出:<br/><b>准备好的训练批次</b><br/>「已裁剪并包含所有特征」"]);
end
style H fill:#fff9c4,stroke:#fdd835,stroke-width:2px
style I fill:#e8f5e9,stroke:#43a047,stroke-width:2px
style K_OUT fill:#dcedc8,stroke:#689f38,stroke-width:4px
图二:模型训练与参数更新流程
这张图则展示了当一个准备好的训练批次输入到模型后,模型内部如何进行计算、评估误差,并最终更新自身参数的循环过程。
graph TD
subgraph "图二:模型训练与参数更新"
A["输入:<br/><b>准备好的训练批次</b><br/>「来自图一」"] --> L["<b>Affinity模块</b>"];
subgraph L["Affinity模块内部"]
direction TB
L1["界面聚焦的PairFormer<br/>「4/8层」"] --> L2["双预测头<br/>「结合可能性 & 亲和力值」"];
end
L --> M{"计算总损失 「L_total」"};
subgraph M["损失函数构成"]
direction TB
M1["成对差异损失 L_dif<br/>「高权重」"];
M2["绝对值损失 L_abs<br/>「低权重」"];
M3["二元分类损失 L_binary<br/>「Focal Loss」"];
end
M --> N["<b>反向传播</b><br/>「仅更新Affinity模块权重」"];
N --> O((下一个训练批次...));
end
style A fill:#dcedc8,stroke:#689f38,stroke-width:2px
style L fill:#fce4ec,stroke:#d81b60,stroke-width:2px
style M fill:#ffebee,stroke:#e53935,stroke-width:2px
style N stroke-dasharray: 5 5
虚拟筛选
mindmap
root(Boltz-2 虚拟筛选)
::icon(fa fa-search-dollar)
**回顾性筛选**<br/>「验证模型基础性能」
数据集: **MF-PCBA**
核心结果: **性能大幅领先**<br/>「平均精度翻倍, 富集因子达18.4」
**前瞻性筛选「TYK2靶点」**<br/>「展示真实世界应用成果」
验证方法: **Boltz-ABFE**<br/>「AI驱动的高精度绝对FEP」
核心发现1: **生成式流程更优**<br/>「发现更高亲和力的分子」
核心发现2: **AI的“创造力”**<br/>「生成了化学新颖且合理有效的分子」
**筛选工作流与方法**<br/>「两种互补的筛选策略」
固定库筛选
对商业库「如Enamine HLL」进行穷举打分
使用并行Boltz-2 workers加速
生成式筛选
模型组合: **Boltz-2 + SynFlowNet**
异步训练闭环<br/>「生成→打分→训练→再生成」
奖励函数: **Boltz-2亲和力分数**
目标: 探索巨大的可合成化学空间
Limitations
mindmap
root(Boltz-2的局限性 与未来方向)
::icon(fa fa-triangle-exclamation)
)分子动力学「MD」预测(
性能未显著超越基线 「与AlphaFlow, BioEmu等专门模型相比」
原因1:MD数据集**规模相对较小**
原因2:**训练后期**才引入MD数据
原因3:针对多构象的**架构改动较小**
)亲和力预测的依赖性(
**核心依赖** 亲和力预测的准确性 高度依赖上游结构预测的质量
**失败模式1** 口袋或界面重构不准确
**失败模式2** 未明确处理**辅因子** 「离子、水分子、其他结合伴侣」
**失败模式3** 亲和力模块的**裁剪尺寸不足** 「可能截断长程相互作用或变构口袋」
)通用结构预测(
与前代模型「如Boltz-1」性能相似
原因:结构训练数据和架构设计大体相同
难以捕捉**大的构象变化** 「如结合诱导的构象变化」
对大型复合物的复杂相互作用预测仍具挑战
)亲和力预测的适用范围(
在不同实验和靶点上**性能差异巨大**
**性能差异的来源待研究**
上游结构预测不准确?
对某些蛋白家族泛化能力有限?
对分布外的化学空间不够鲁棒?